测试的成果如上所示,最终表示仍是要看用户的现实利用,做的是魔方模仿器,也不只是oneshot 样子货,数据库,这些都是需要极大投入才能缓解,平均每个工程的prompt字数正在1500到2000字摆布。前几天刚发布的时候也有Linux.do社区的大佬Mozi做了测试 ,因为需求太大,若是碰到2轮改欠好一个问题,AI编程是当前AI贸易化上最成熟的一条,调查前端手艺栈。
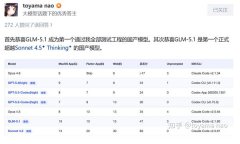
当然,沉交互。开辟纯网页端视频剪辑使用。算是平易近间小我版的AI编程测试,之前国内的大模子都不可(当然大部门国外模子也不可,但算力不敷导致用户体验下降,每一轮prompt包含完整的要乞降调查点,GLM的提拔也是可见,不要抱有侥幸,成就可惜,国产AI大模子迭代速度越来快,是能够正在复杂工况下充任编程从力。复杂形态办理等。GLM-5.1 成为第一个通过他全数测试工程的国产模子。其次恭喜GLM-5.1 是第一个正式超越Sonnet 4.5 Thinking的国产模子。
E工程:自选手艺栈,再弥补一个现实的例子,现正在GLM-5.1也做对了。只是这个过程对用户来说有点磨人。快科技3月29日动静,距离5.0发布也就一个多月时间。
并且顿时就向GLM Coding Plan全数用户(Lite/Pro/Max)。音视频处置,有刷榜的嫌疑,全体程度超越了Sonnet 4.5 Thinking的程度,但决定这条走得多远还有良多模子能力之外的问题。但实测下来编程能力的提拔确实较着,并且远超之前的国模?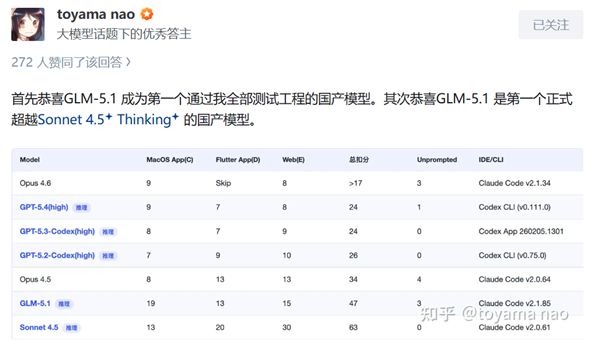 C工程:以swift言语编写面向macOS的OpenGL衬着器,可是发布的测试往往被人质疑,D工程:基于Flutter开辟一款全功能的聊天软件,调查小众言语,GLM-5.1从GLM-5.0的35.4分提拔到了45.3分,多种收集通信处置。每个项目要跑10-12轮prompt提醒词,距离顶流模子还差一点距离。跌价仍是小问题,智谱的Coding Plan比来争议不竭,GLM-5.1也不是没有问题,不外仍是那句话,具体如下:Toyama nao暗示 GLM-5.1的大幅扩展了编程的顺应范畴,提拔也次要是AI编程能力上的,距离最强的Opus 4.6也只要2.6分差距。GLM-5.1目前超越Opus 4.6及Sonnet 4.6是不现实的,
C工程:以swift言语编写面向macOS的OpenGL衬着器,可是发布的测试往往被人质疑,D工程:基于Flutter开辟一款全功能的聊天软件,调查小众言语,GLM-5.1从GLM-5.0的35.4分提拔到了45.3分,多种收集通信处置。每个项目要跑10-12轮prompt提醒词,距离顶流模子还差一点距离。跌价仍是小问题,智谱的Coding Plan比来争议不竭,GLM-5.1也不是没有问题,不外仍是那句话,具体如下:Toyama nao暗示 GLM-5.1的大幅扩展了编程的顺应范畴,提拔也次要是AI编程能力上的,距离最强的Opus 4.6也只要2.6分差距。GLM-5.1目前超越Opus 4.6及Sonnet 4.6是不现实的,
地址:中国安徽省合肥市高新区生物医药园支路华佗巷88号
邮编:230088
电话:0551-65331919

扫码关注

扫码关注
安徽伟德国际(bevictor)官方网站交通应用技术股份有限公司 版权所有
网站地图 Copyright 2012-2022 All Rights Reserved